
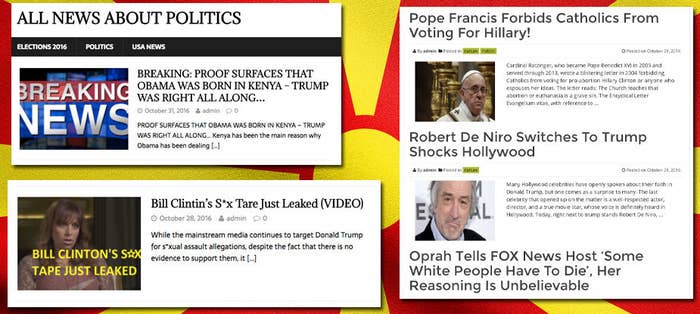
Social media was supposed to make the world more open and connected. Instead, it tore us apart, with bots, trolls, and state-sponsored bad actors spreading fake news and toxic hatred.
At Twitter, where I worked until 2016, I helped build something that could point the way toward a solution — machine learning systems working together with human moderators to make a filtering system that works at scale, learns from its mistakes, and improves over time.
The product we built, Twitter Moments, prioritizes trustworthiness and quality, and for the most part delivers fake-news-free content — both banal and serious — using skilled human moderators in a scalable fashion. The decision to use that human curation looks better every day.
Before talking about the way forward, it’s worth being clear about how we got here. Major social platforms like Facebook and Twitter use ranking algorithms to automatically select an ordered list of posts for each user’s stream. Machine learning powers these algorithms, enabling them to learn from both historic data and their decisions, over time optimizing whatever metrics their programmers have selected.
We call this goal an objective function. Most social networks choose engagement: a combination of actions taken by users to share or favorite a post, the time/intensity they spent interacting with the content, and, for ads, how much the advertiser is willing to pay. Machine learning algorithms care ONLY about components of their objective functions: They will automatically and blindly maximize the time people spend engaging with content, indifferent to whether that means showing a user mendacious foreign propaganda or the latest peer-reviewed scientific paper.
These models optimize platforms with billions of users, matching content to small sets of people interested in it regardless of the size or geographic characteristics of each set — something that used to be prohibitively expensive. This new, effective, efficient, automatic, and cheap way for authors to reach audiences has resulted in a collapse in content distribution costs, leaving production costs as the dominant factor. Similar to other industries, this has weakened traditional businesses that exploited high distribution costs by aggregating audiences and serving them mass-market content.
Consider the following (simplified) example of junk news spreading :
Alice is shown content that is radical or fake, and liked by 100 people. (“One scientist reveals the truth: The Earth is flat!”)
She engages with this content by spending 10 minutes reading the article, comments on it, and possibly clicking "like."
The machine learning model then infers that she likes this kind of content, and will, in the future, suggest similar content — perhaps from the same source or content that others who liked the flat Earth article also liked. (“Scientists are lying: gravity is an illusion!” “Vaccines cause autism!”)
Alice’s friends are shown the flat earth article with tag “Your friend Alice liked this!”
Machine learning models combine with human nature to produce bad second order effects. People like engaging with salacious content, and tend to believe it’s true when presented with strong social proof. Over time, a recommendations system using a truth-agnostic ranking algorithm, if given a large number of users and an endless supply of cheap content, will create a system that is easily exploited to spread fake news and radicalize many of its users.
What can we do about this? Ensuring that every piece of content is reviewed for accuracy simply won’t work on a platform with hundreds of millions of users and an ever-growing number of content producers. It’s much cheaper to write fake content than to verify its accuracy.
Twitter Moments focused on stories of interest to a broad set of users. Madhu Muthukumar, the product manager at the time, researched the number and scope of articles published by newspapers each day (it's around 1,000 each) to figure out how much curation work could have plausibly been done by a team of human editors. Andrew Fitzgerald, an experienced journalist who worked as our curation lead, created and led a team of curators with relevant backgrounds. Using internal tools (some of which are now available to the public) they reviewed and selected the best content for Moments.
Combining machine learning ranking algorithms with human editors would allow platforms to scale intelligent curation to increasing amounts of content: We need to train our computers to think and act like real editors. Historical human curation decisions must be added to objective functions. Ranking algorithms will then optimize not only engagement, but also whether content would have been selected by curators. This, in essence, amplifies the reach of human editorial decision-making, allowing platforms to better curate large amounts of content. It couldn’t reach it all, but it could go a long way, particularly on the biggest news topics of the day.
Additionally, human curators should be tapped to review posts when they begin to spread within the network, when the algorithm lacks confidence, or based on user-generated signals that the content is suspicious or fake. Again, the decisions humans make can be fed back into the system, which would then learn from curators, users, and its own mistakes.
Even if they work perfectly, these ranking algorithms will only amplify the decisions of the human curators. Deciding between real vs. fake, permissible vs. forbidden, abuse vs. speech can often be very difficult. Machines can’t do this for us; we must empower people to make these decisions. Just like Tony Stark's Iron Man suit, we need tools that make humans more powerful and scalable, rather than ones that replace them with robots. The true power lies in the leaders of these platforms; it’s up to them to decide what they will and won’t tolerate.
Vijay Pandurangan is an investor and founder, and most recently an entrepreneur in residence at Benchmark Capital. Previously, he was a director of engineering and the NY engineering site lead at Twitter.