
The great Yanny and Laurel conspiracy theory was hatched when Jay Rose saw a New York Times story about the sound that broke the internet. The article included a "spectrogram," a chart of all the frequencies in the 1-second clip.
“I looked at it and I said, That’s not right,” Rose told BuzzFeed News. The splotches of red and yellow showed combinations of frequencies that don’t naturally go together — ever. “Humans do not make that particular sound when they’re speaking language.”
Rose has been a sound engineer, teacher, and textbook writer for nearly five decades. He’s worked on films for Disney and commercials for McDonald’s and has edited the voices of Barney and Big Bird. He’s seen thousands of spectrograms in his career. And he was positive that this Yanny/Laurel thing could not have come out of a human mouth.
Rose shared his discovery with Pascal Wallisch, a neuroscientist at New York University, who’s studied why people see different colors in the Dress. The duo discussed the technical specs of the viral recording — the “Frankensound,” as Wallisch dubbed it. They both got excited and hatched an outlandish theory: What if the recording was not made by an opera singer for Vocabulary.com, as reported in the press, but was instead a PR stunt by a company looking to ride the latest internet sensation?
To get to the bottom of this mystery, Rose carried out a series of experiments from his home studio outside of Boston, enlisting the help of other sound geeks, professional actor Will Lyman (best known as the voice of the PBS series Frontline), and a journalist (me). And after an eight-day investigation, Rose found an answer he was never expecting.

After seeing the New York Times story, Rose posted a hypothesis on a message board for audiophiles: that the recording came not from a person but from “a badly implemented speech synthesizer” — a computer program that mimics speech.
As the message board lit up with discussion, Rose wrote to Wallisch with his idea. The two men didn’t know each other, but Wallisch was immediately intrigued. (“This is quite the scoop,” he wrote me the next day. “Actual #Yannygate.”)
Meanwhile, one of the founders of Vocabulary.com was talking to the press about how the “laurel” recording came to be. CTO Marc Tinkler told Wired that when the site was first getting started, back in 2007, "We hired a bunch of opera singers to record 200,000 words, basically." These trained actors knew how to read the International Phonetic Alphabet, the gold standard guide for pronouncing words in any language. As the company explained on its blog, five actors went through this long, “grueling” process. Jay Aubrey Jones, for example, who was once an understudy in the Broadway musical Cats, pronounced more 36,000 words, including “laurel.”
But Rose wasn’t so sure. As he explained in emails to Wallisch, the IPA has just 46 “phonemes” — distinct units of sound — that show up in standard American English pronunciations. And there was no possible combination of those 46 sounds that would result in the “laurel” spectrogram.
Rose and Wallisch didn’t know how to square those facts with the company’s claims about the opera singers. Perhaps the singers recorded only a fraction of the words on the site, and then those files were used to train a computer to produce the rest. That “would be a lot more efficient on their servers,” Rose told his message-board friends, “but I can't blame the site for wanting to milk the story and create more buzz.”
“The most likely version is that someone cut corners somewhere, once they realized they have to do this 200,000 times,” Wallisch wrote me by email. “The really cool thing is that LaurelYanny then is — at heart — a failure of machine learning (!).”
Rose’s first opportunity to test his theory came when NPR interviewed Jones about his experience recording “laurel” a decade earlier.
Luckily, Jones said the words “laurel” and “yanny” while in the NPR studio. So Rose downloaded the interview file and compared the spectrograms for each of those words with that of the viral clip. Here’s what he found:
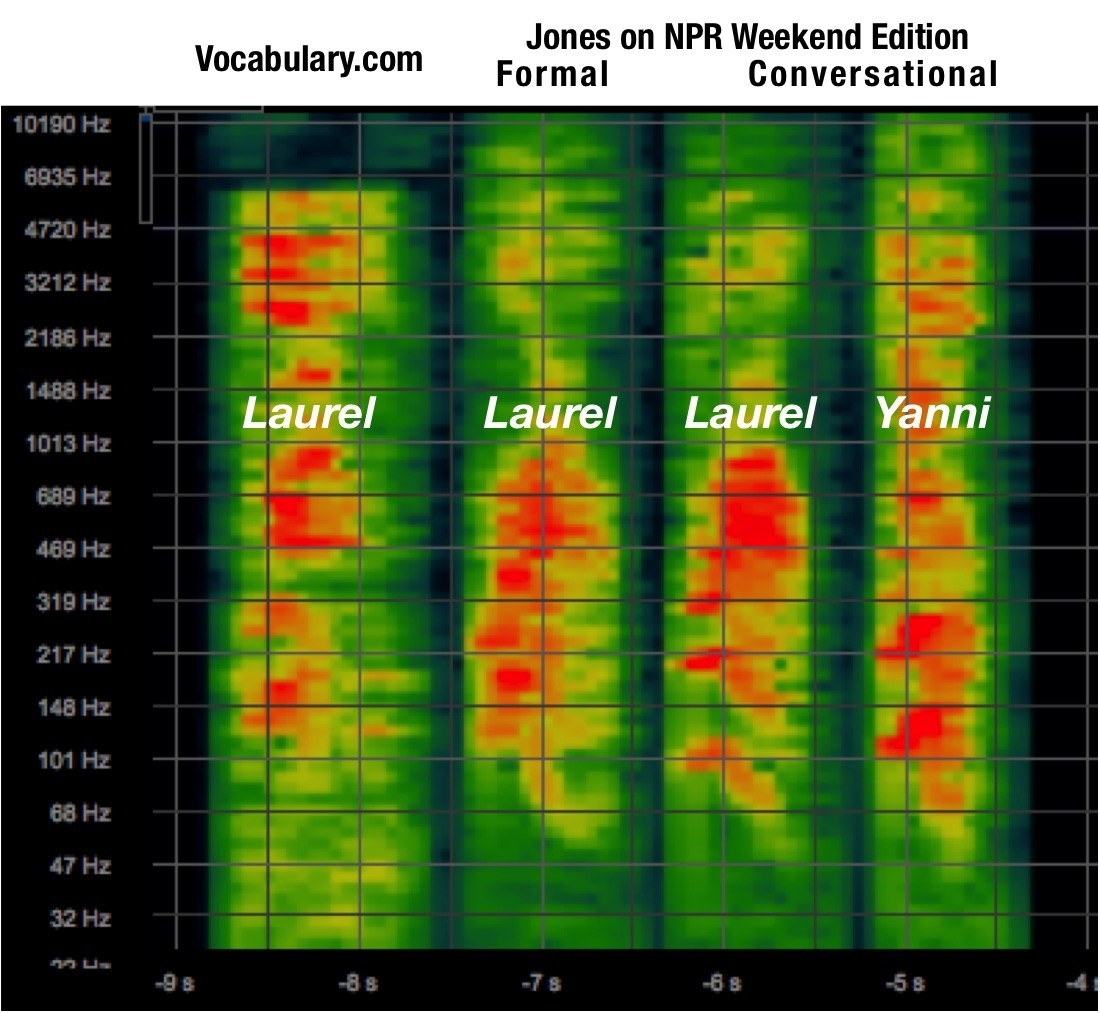
The range of human hearing spans roughly from deep bass notes of 20 hertz (which vibrate against the eardrum 20 times per second) to high squeals of about 16,000 hertz. As Rose had predicted, the “laurel” from Vocabulary.com contained both the low-frequency notes of that word and the higher frequencies of “yanny.” The NPR recordings of Jones’ words were all one or all the other, lacking this overlap.
Because the Vocabulary.com version of the word contains some frequencies characteristic of a human-produced “laurel” and other frequencies characteristic from a human “yanny,” the brain doesn’t know how to choose — a psychological phenomenon that tore a nation apart.
(As an aside, Wallisch is now recruiting volunteers for a study to find out whether there are lifestyle or personality factors that explain why some hear “yanny” and others “laurel.” You can be part of his study by clicking here.)
So now Rose knew that there was something strange going on with the “laurel” recording on Vocabulary.com. But what about other words on the website? And what about pronunciations on a similar site, Dictionary.com?
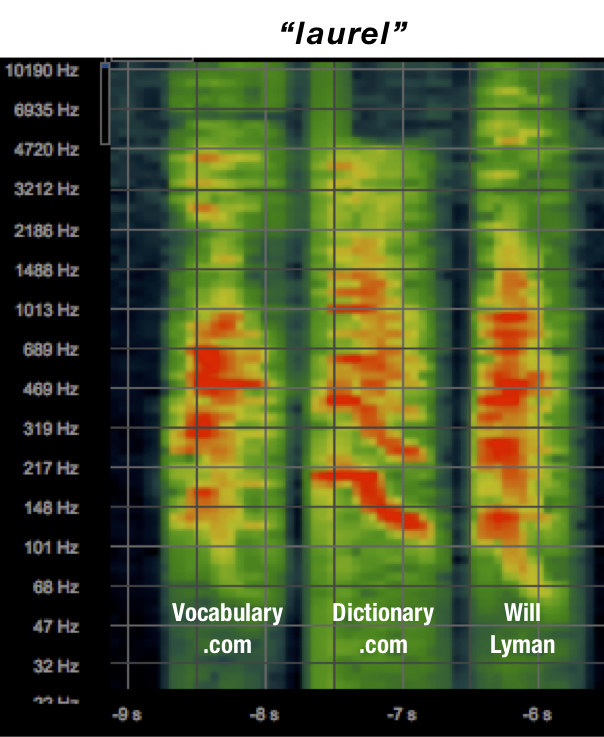
He chose a handful of words that sound like “laurel” — “lawyer,” “lawn,” and “loss,” — and others that sound like “yanny” — “yawn,” “yaw,” and “Yana.” He pulled all of these pronunciations from both websites, and asked an old friend from the biz, Will Lyman, if he’d record each of these words for him.
As it turned out, the spectrograms for Dictionary.com’s words and Lyman’s words were very similar. And the spectrograms for Vocabulary.com’s words and Lyman’s words were also very similar — except for the infamous “laurel.”
Then Rose did yet another comparison: this time between Vocabulary.com’s “laurel” and its “Lorelei,” which have the same first syllable and were both originally recorded by Jones. And yet again, the odd frequency patterns only showed up in the site’s “laurel."
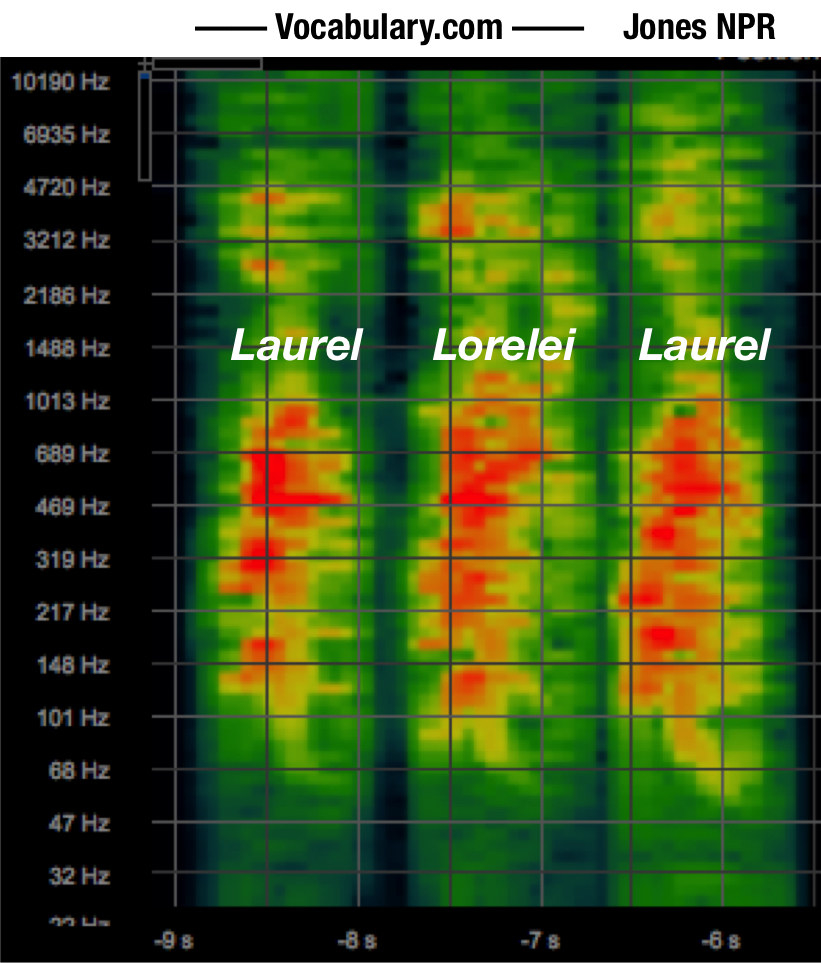
Now Rose knew: The problem didn’t stem from Jones’ voice or from a systemic issue in the way Vocabulary.com compressed or stored its sounds. And it probably wasn’t a badly trained speech synthesizer, either, as the computer program would have likely treated “Lorelei” the same as “laurel.”
It was just a glitch in this one word. But why?
At this point, Rose told me he was ready to go public with his data, so I called a couple of sound experts to get their take. “I agree with Jay Rose 100%,” said Ed Primeau, a Michigan-based audio forensic expert who helped track down the real voice of Siri.
“There is definitely something strange about the audio,” said Andrew Oxenham, a professor of psychology and otolaryngology at the University of Minnesota. But he wasn’t sure whether it was a faulty speech synthesizer or a bad recording of a real human.
I finally called Tinkler, the cofounder of Vocabulary.com, and asked: Had his company been using a speech synthesizer to create the pronunciations?
“I can tell you without reservation that that did not happen,” Tinkler said, chuckling. It was undoubtedly true that being at the center of a viral storm brought his company welcome attention. (They even added “yanny” as a joke entry.) “Can’t complain,” he said.
Tinkler also told me a few more details about how the recordings were made in 2007. The actors did them from home, using a laptop, a “really nice microphone,” and pieces of foam to help with soundproofing. The computer would show them each word in IPA. They’d say the word and then immediately send the recording over the internet to Vocabulary.com’s servers for further processing.
Tinkler didn’t really know why the “laurel” spectrogram looked so unusual but guessed that it had something to do with the “aggressive” compression methods they used back in 2007. He offered to share the archived file with Rose for further analysis, and I put them in touch.
The two engineers exchanged emails back and forth, getting into the technical nitty-gritty. The archived file, unfortunately, was not the raw original — it had gone through some amount of processing, and its spectrogram had the same weird patterns.
Then Rose brought up the downside of using foam as a DIY sound booth. If there had been any noise outside of Jones’ home, he pointed out, it would probably end up in the recording.
Bingo. Tinkler remembered having particular problems with a bunch of Jones’ recordings because of ambient noise. The site's sound engineer tried to remove the noise with open-source software, but Rose knew that software and knew that back in 2007 it was “notoriously slow and difficult for even top sound engineers to operate,” as he wrote on a blog post about the whole story.

“So I think there was some outside noise — possibly a truck's brakes — generating transitory noises that provided the extra ‘yanni’ frequencies,” Rose wrote. And then the noise-reduction software morphed those extra frequencies into something resembling a human voice.
With the original recording lost to history, no one will ever know for sure. But Rose was satisfied. Wallisch seemed a little disappointed that the answer was so banal. But he took a philosophical lesson from the whole saga: If you do something often enough — like recording 200,000 words into a microphone — then, eventually, an extremely unlikely event will happen by chance.
It’s why someone wins the lottery every week, he said, and why an Alexa machine happened to record one family’s private conversations. “A truck goes by at just the right time...” he said, and you wind up with a killer internet meme.
But what if North Korea were to mistake sunlight reflecting off clouds as an incoming nuclear weapon, as almost happened to the Russians in 1983? It’s “scary if nukes are in play,” Wallisch said. “Frankly, it is a miracle we are all still here.”